const - JS | lectureHow JavaScript Works Behind the Scenes
The JavaScript Engine and Runtime

In the last lecture, we had a broad overview of JavaScript. This lecture will explain some topics we saw in the previous lecture, such as the JavaScript engine, the JavaScript runtime, and how JavaScript code is translated to machine code.
A JavaScript engine is a computer program that executes JavaScript code. There are a lot of steps involved in doing that, but essentially executing JavaScript code is what an engine does.
Every browser has its JavaScript engine, but the most well-known engine is Google's V8. The V8 engine powers Google Chrome and Node.js, the JavaScript runtime used for building server-side applications with JavaScript outside of any browser.
It's quite easy to understand what an engine is, but the most important is understanding its components and how it works. Any JavaScript engine always contains a call stack and a heap.
The call stack is where our code is executed using something called execution context. The heap is an unstructured memory pool that stores all the objects our application needs.
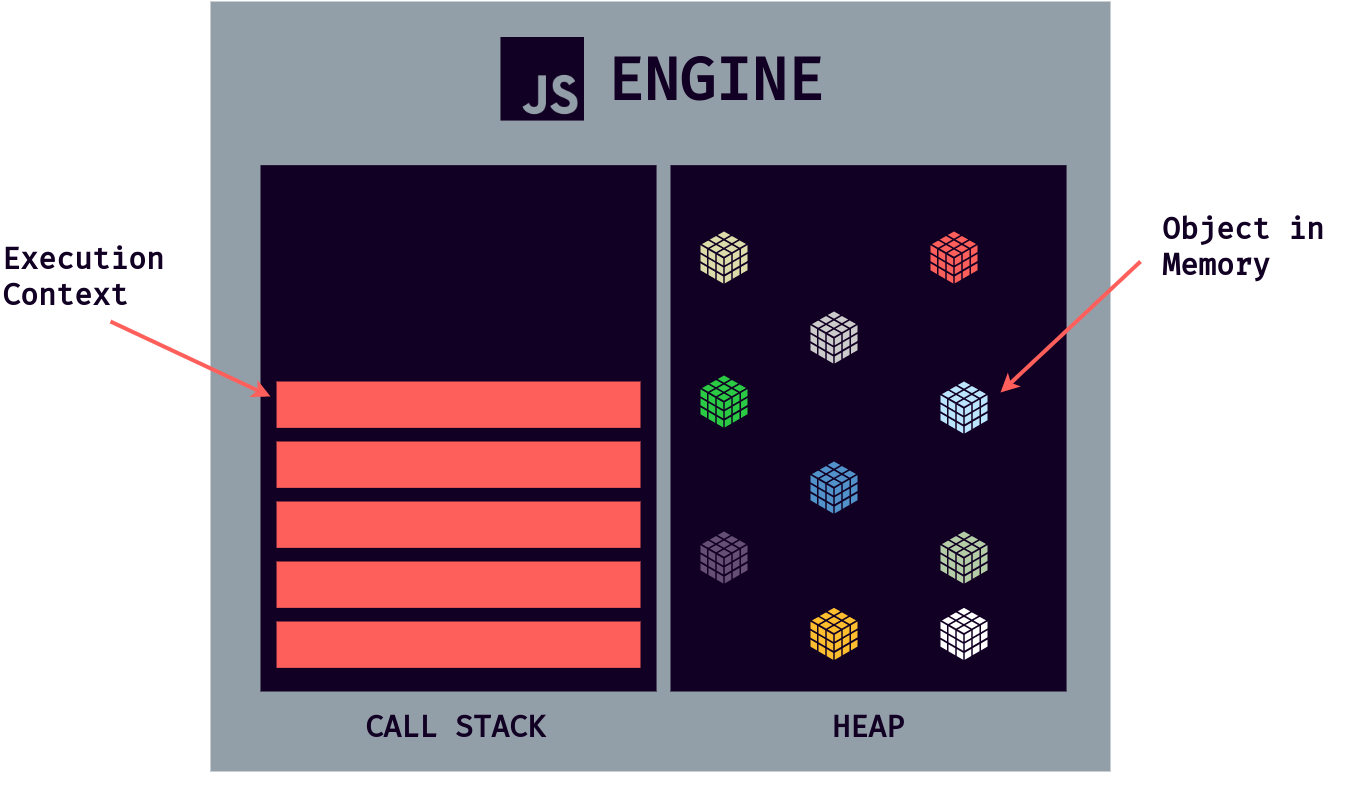
We have answered where our code is executed with this look at the engine. But now the question is, how is the code compiled to machine code to be executed afterward?
We first need to make a quick computer science refresh and talk about the difference between compilation and interpretation to answer that question.
We learned that the computer's processor only understands zeros and ones in the last lecture. Therefore, every computer program must be converted into machine code, using compilation or interpretation.
In compilation, the entire source code is converted into machine code at once. This machine code is then written into a portable file that can be executed on any computer.
We have two different steps here: first, the machine code is built and then executed in the CPU .i.e in the processor. The execution can happen way after the compilation. For example, any application you're using on your computer right now has been compiled before, and you're now executing it way after its compilation.

On the other hand, in interpretation, an interpreter runs through the source code and executes it line by line. Here we do not have the same two steps as before. Instead, the code is read and executed all at the same time.

The source code still needs to be converted into machine code, but it simply happens right before it's executed and not ahead of time.
JavaScript used to be a purely interpreted language, but the problem with interpreted languages is that they are much slower than compiled languages. This used to be okay for JavaScript, but now with modern JavaScript and fully-fledged web applications that we build and use today, low performance is no longer acceptable.
Just imagine you were using Google Maps in your browser, and you were dragging the map, and each time you dragged it would take one second for it to move. I think we can agree that it would be completely unacceptable.
Many people still think that JavaScript is an interpreted language, but that's not true anymore. Instead of simple interpretation, modern JavaScript engines now use a mix between compilation and interpretation called Just-In-Time (JIT) compilation.
This approach compiles the entire code into machine code at once and then executes it right away. We still have the two steps of regular ahead of time compilation, but there is no portable file to execute, and the execution happens immediately after a compilation, which is perfect for JavaScript as it's a lot faster than just executing code line by line.

Some details were omitted, but this is all you need to know. Let's now understand how this works in the particular case of JavaScript.
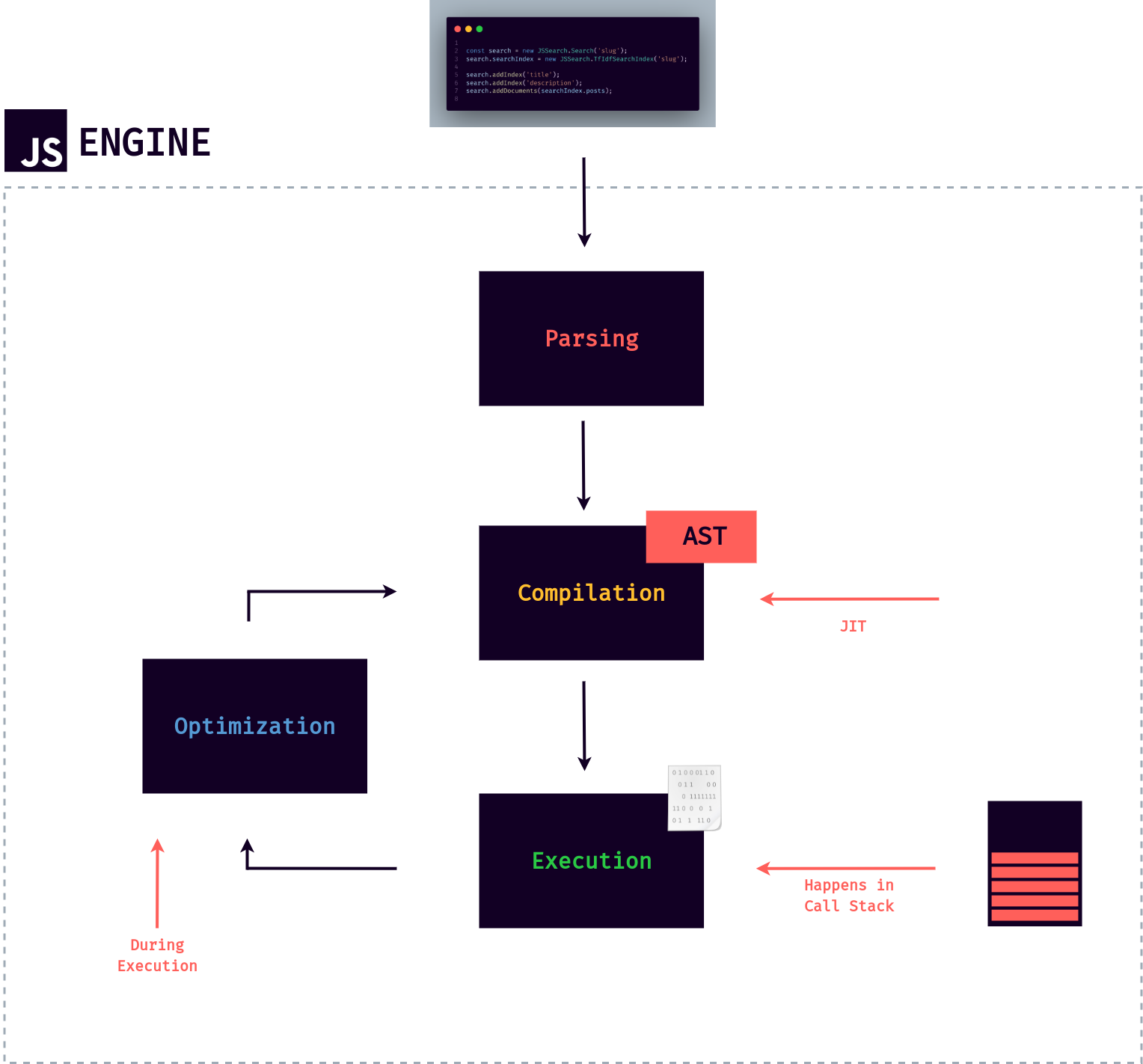
As a piece of JavaScript code enters the engine, the first step is to parse the code, which essentially means to read the code. During the parsing process, the code is parsed into a data structure called the Abstract Syntax Tree or AST.
This works by first splitting up each line of code into pieces that are meaningful to the language, like the const or function keywords, and then saving all these pieces into the tree in a structured way. This step also checks if there are any syntax errors, and the resulting tree will later be used to generate the machine code.
const user = 'Ulrich';Let's consider the below code and its corresponding AST

From the above, we have a variable declaration (VariableDeclaration) which should be a constant (kind: "const") with the name user (name: "user") and value "Ulrich" (value: "Ulrich").Besides that, there is a lot of other stuff here, as you can see. Just imagine what it would look like for a real large application. Before moving on, I want to let you know that you don't have to know what an AST looks like. This was just to let you know that it exists.
You have to keep in mind that the AST has nothing to do with the DOM tree. They are not related in any way. The AST is just a representation of our entire code inside the engine.
After parsing, the next step is compilation, which takes the generated AST and compiles it into machine code, just as we learned. This machine code then gets executed right away because, if you remember, modern JavaScript engines use just-in-time compilation.
Again, remember that execution happens in the JavaScript engine's call stack, but we will dig deeper into this in the next lecture.
Now you might think that we are done, and we can finish here since our code has already been executed. Well, not so fast because modern JavaScript engines have some pretty clever optimization strategies. They create a very unoptimized version of machine code in the beginning, to start executing as fast as possible.
Then, the code is being optimized and recompiled during the already running program execution in the background. This can be done multiple times. And after each optimization, the unoptimized code is swept for the new, more optimized code without ever stopping execution.
This process is what makes modern engines such as the V8 so fast. All this parsing, compilation, and optimization happens in some special threads inside the engine that we cannot access from our code. That is, it is completely separate from the main thread that is running in the call stack executing our code.
Different engines implement this in slightly different ways, but in a nutshell, this is what modern just-in-time compilation looks like for JavaScript.
Below is a diagram summarizing all we just said above.
To finish this lecture, let's also look at what a JavaScript runtime is, particularly the most common one, the browser, and by doing this, we can get the bigger picture of how all the pieces fit together when we use JavaScript.
We can imagine a JavaScript runtime as a big box or a big container that includes all the things we need to use JavaScript in this case, in the browser.
At the heart of any JavaScript runtime is always a JavaScript engine. Exactly the one we've been talking about. That's why it makes sense to talk about engines and runtimes together.
Without an engine, there is no runtime and there is no JavaScript at all. However, the engine alone is not enough. In order to work properly, we also need access to the Web APIs. That's everything related to the DOM
or timers or even the console.log that we use all the time.
Essentially Web APIs are functionalities provided to the engine but are not part of the JavaScript language itself. JavaScript gets access to these APIs through the global window object. But it still makes sense that the Web APIs are also part of the runtime because, again, a runtime is just like a box that contains all the JavaScript-related stuff that we need.
Next, a typical JavaScript runtime also includes a so-called callback queue.
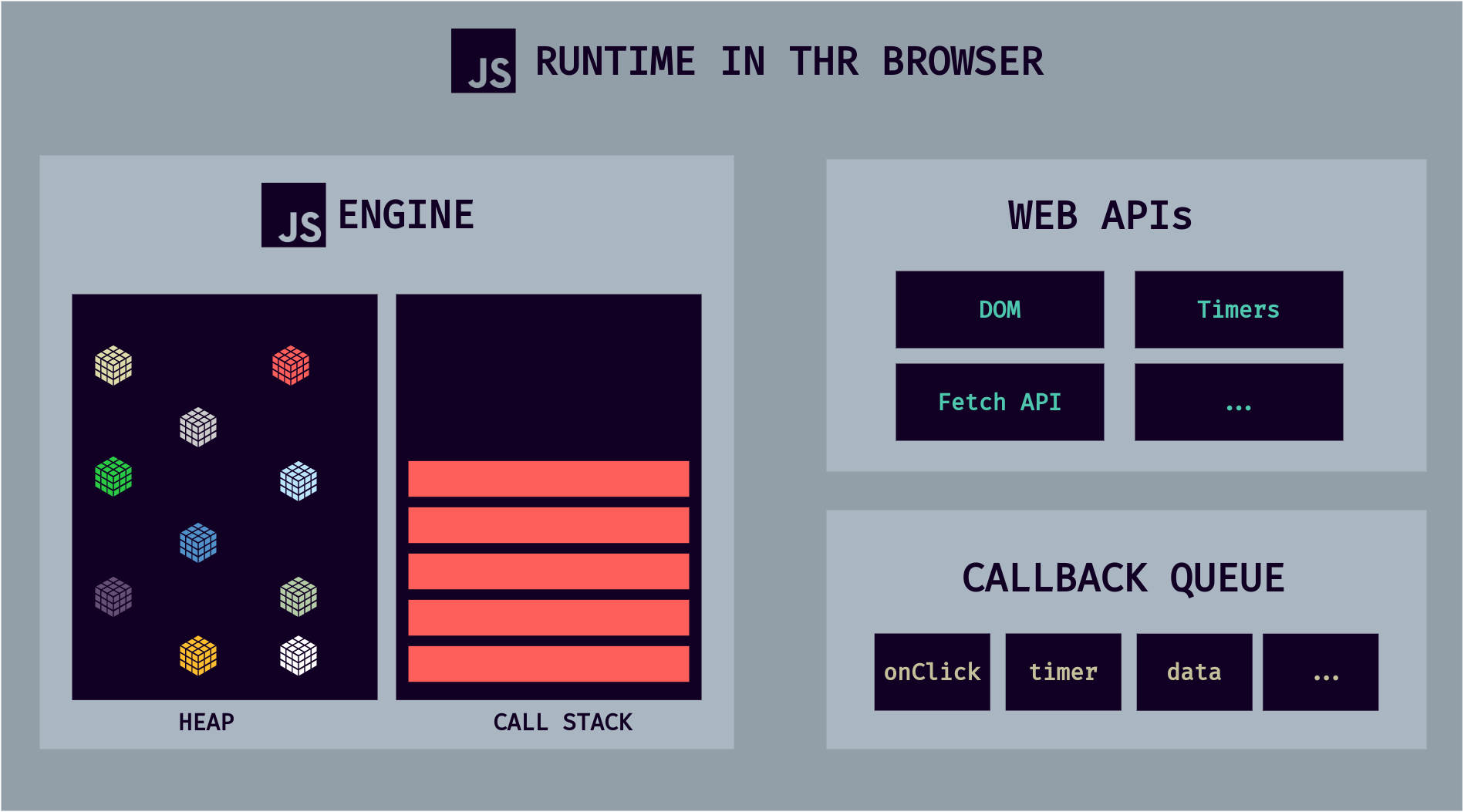
A callback queue is a data structure contains all the callback functions that are ready to be executed.
For example, when we attach event handler functions also known as callback functions to DOM elements like a button to react to certain events, as the event happens, for example a click, the callback function will be called. Here is how that works behind the scenes.
The first thing that happens after the event is that the callback function is put into the callback queue. Then, when the stack is empty, the callback function is passed to the stack so that it can be executed.
This happens by something called the event loop (Essential for non-blocking concurrency model 👌). The event loop takes callback functions from the callback queue and puts them in the call stack to be executed.

We will go over why this makes JavaScript nonblocking in a special lecture about the event loop later. This is a fundamental piece of JavaScript development that every developer needs to understand deeply.
As already mentioned, the focus in this course is on JavaScript in the browser, and that's why we analyzed the browser JavaScript runtime. However, it's also important to remember that JavaScript can exist outside of browsers, for example, in NodeJS.
Here is what the NodeJS JavaScript runtime looks like.

It's pretty similar, but since we don't have a browser, we can't have the Web APIs because the browser provides these. Instead, we have multiple C++ bindings and a so-called thread pool.
Details don't matter here at all. What you need to know is that different JavaScript runtimes do exist. In the next lecture, we will learn how JavaScript is executed in the call stack.